
¿Qué es la complejidad temporal?
Una explicación simple sobre la complejidad temporal
En ciencias de la computación se estudian las propiedades de los algoritmos. La complejidad temporal es una de estas propiedades y se utiliza mucho en la práctica porque la eficiencia de los algoritmos que creamos es un factor muy importante. Ya que se traduce en un costo directo en la operación de un sistema o aplicación. Si un algoritmo puede realizar el mismo trabajo que otro pero utilizando menos recursos vamos a usarlo para reemplazar al menos eficiente.
La complejidad temporal no es una medida de cuánto tarda en ejecutarse un algoritmo sino de cómo varía el tiempo de ejecución cuando existe una variación en la cantidad de datos de entrada. Es decir, no nos importa si el algoritmo realiza su trabajo en un minuto o en dos horas, sino cuánto más tarda en correr cuando hay diez datos en la entrada comparado con cuánto tarda con dos datos en la entrada. Desde luego que los número que acabamos de utilizar son arbitrarios e irrelevantes. Lo importante es el concepto. La complejidad temporal no tiene unidad, es una medida relativa.
Además de la complejidad temporal existe también la complejidad espacial que representa la variación del consumo de memoria del algoritmo según la variación en la cantidad de datos de entrada. Si comprendemos correctamente la primera vamos a haber comprendido la segunda en forma indirecta porque la idea detras de ellas es idéntica. Por supuesto que cuando estudiamos el algoritmo vamos a hacer observaciones diferentes para calcular cada una. Pero al igual que la complejidad temporal, la complejidad espacial no tendrá una unidad de medida (como por ejemplo bytes) porque es una medida relativa.
Imaginemos un algoritmo del cual no nos importan sus detalles internos por el momento. Lo consideraremos una caja negra de la cual sabemos la cantidad de datos de entrada que recibe y el tiempo que tarda en finalizar su ejecución. Con esto podemos perfectamente estudiar la complejidad temporal realizando una serie de ejecuciones y sacando una conclusión. Esta no es la forma típica en la que se calcula la complejidad de un algoritmo. Pero es ideal para poder explicar el concepto sin tener que entrar ahora mismo en los detalles engorrosos.
Empecemos por ejecutar el algoritmo para un dato de entrada. Aquí vamos a hablar de una cantidad de datos de entrada asumiendo que estos son equivalentes entre sí. Por ejemplo en un algoritmo que ordena números enteros la cantidad de datos de entrada sería la cantidad de números enteros que pasamos al algoritmo para que ordene. En general a esta cantidad la llamamos n. Si el algoritmo puede recibir un número variables de dos tipos de datos distintos, a uno lo llamaremos n y al otro m. Y así a medida que existan más tipos de entradas relevantes. No nos interesan otras entradas que no vaya a afectar el tiempo de ejecución. Si el algoritmo recibe un nombre de archivo para escribir la salida, ese dato no es relevante.
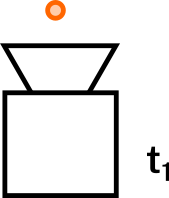
Definamos como t1 al tiempo que le tomó al algoritmo ejecutarse para un dato de entrada. Luego ejecutemos el algoritmo para otras cantidades:
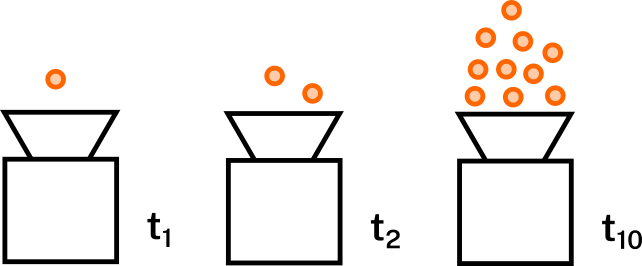
De donde obtendremos t2 y t10 también. Como ya explicamos no nos importa realmente el valor en unidad de tiempo de cada una de estas medidas. Lo que queremos es comprarlas entre ellas. Así que imaginemos que t1, t2 y t10 dieron el mismo tiempo. Es decir que no hubo variación en el tiempo de ejecución a pesar de la variación en la cantidad de datos de entrada. Estamos ante un algoritmo de complejidad temporal constante. Es básicamente la mejor complejidad temporal que podemos tener. En notación Big O se representa como O(1)
Supongamos que se cambia el algoritmo y se vuelven a ejecutar los tres casos anteriores. Pero ahora t1 dió un tiempo al que llamaremos x, t2 dió 2x y t10 dió 10x. Podemos observar que al duplicar la cantidad de datos de entrada se duplicó el tiempo de ejecución. Y al multiplicar por 10 la cantidad de datos de entrada el algoritmo tardó diez veces más que para uno.
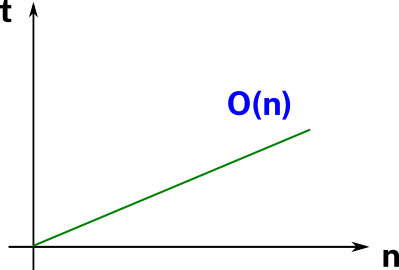
Si graficamos la respuesta en tiempo en función de la cantidad de datos de entrada tendremos una línea recta. La complejidad temporal en este caso es lineal. Ya que el tiempo de ejecución varía linealmente con las variaciones en la cantidad de datos de entrada. En notación Big O se representa como O(n). Y esta complejidad es la ideal entre las que son esperables encontrarnos. Ya que no es muy común que un algoritmo no varíe el tiempo de ejecución a pesar de la variación de la cantidad de datos de entrada. Por lo general eso significa que no está utilizando esos datos.
Si nuestro algoritmo presenta una variación en el tiempo de ejecución como la descripta en la siguiente tabla:
Datos | Tiempo
=======|========
1 | x
2 | 4x
4 | 16x
10 | 100x
Estamos ante una complejidad temporal cuadrática. Que nuestro algoritmo presente esta complejidad temporal es bastante preocupante. Excepto que sepamos que no existe una mejor forma de resolver el problema. Desde luego existen problemas que se resuelven con esta complejidad en el mejor de los casos. Y también otros que se resuelven con peor complejidad como O(n^2) u O(n!) sólo por nombrar dos ejemplos.
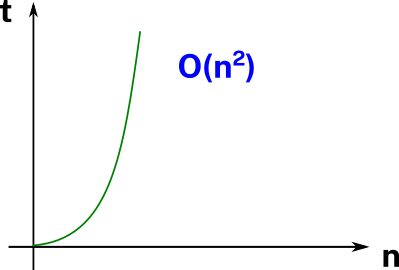
Insisto en usar una
xpara representar el tiempo correspondiente a la ejecución de un elemento para luego expresar el resto en función de éste. Porque de esa forma queda más claro que estamos evaluando la variación relativa entre ejecuciones y no el tiempo concreto.
Conclusión
Hasta aquí pudimos entender conceptualmente la complejidad temporal. Hemos dejado muchas cosas fuera de la explicación para mantenerla simple y accesible. No profundizamos en todas las complejidad típicas, no explicamos cómo podemos estudiar un algoritmo (incluso en pseudocódigo) para determinar su complejidad sin necesidad de ejecutarlo realmente. No explicamos qué es exactamente la notación Big O. Estas cuestiones las trataremos por separado en otros artículos.
Imagen de xkcd.com bajo licencia CC-BY-NC2.5 reformateada para este sitio.