
DRKSpiderJava v0.83
Website crawler stand-alone tool
Description
DRKSpiderJava is a website crawler stand-alone tool for finding broken links and inspecting a website structure. It builds a tree representing the hierarchical page distribution inside the site. Analyzing every link found, including those which point to another domain. Crawling is limited by external links, a maximum depth level given by the user, URL exclusion list, and the optional setting for obeying robots.txt site definition. DRKSpiderJava can keep site’s content in memory (optional) for doing global searches in content. Once the spider finishes its work, the user can export a sitemap, a list of all links and the list of broken links. Every list provides a different amount of information according to the common usage. The output can be XML, plain text or CSV files.
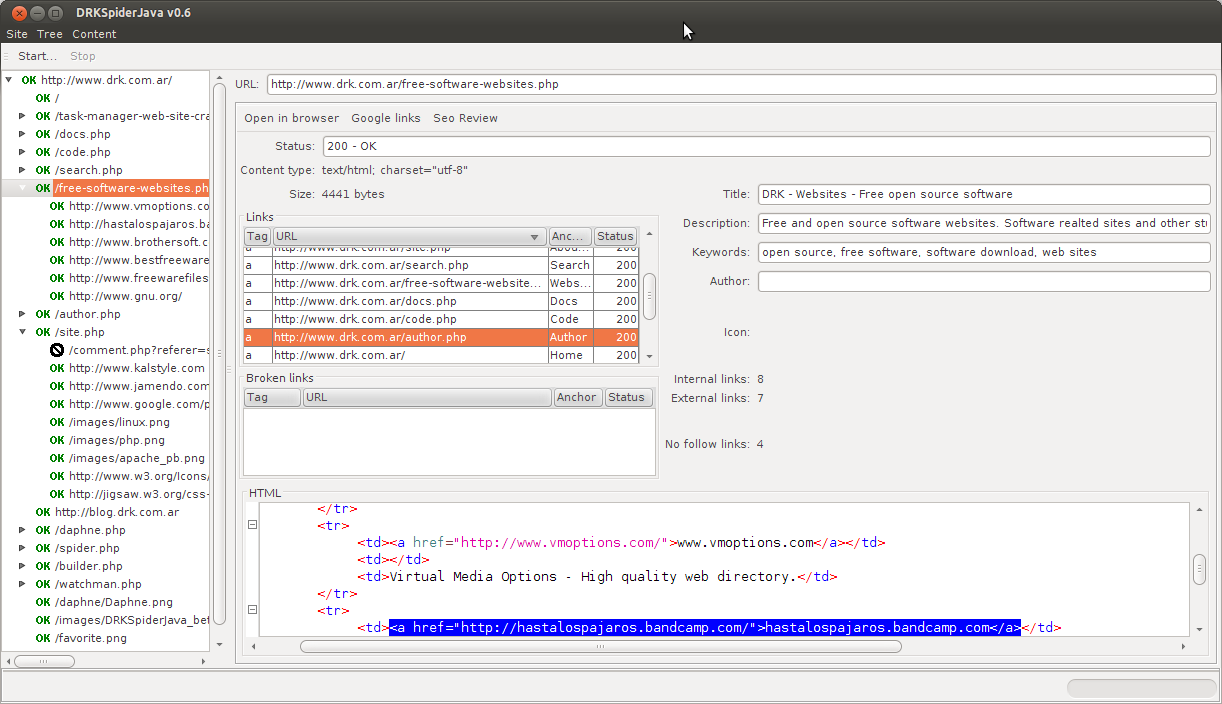
When a node in the tree is selected, DRKSpiderJava displays contextual information in the right panel. For HTML nodes there is a detailed set of items about document metadata, along with the list of links found. Link information is divided into pieces like: link tag, URL, anchor text, nofollow status, link status code, and depth. Clicking over a link in the list selects the text in the document source. This makes easy locating and fixing problems.
There are two advanced search dialogs: one for link searching and other for nodes. The difference between links and nodes is related to the user interface and DRKSpiderJava internal matters. Links are those links shown in the HTML panel, and nodes are items in the navigation tree. There is just one node for every URL in the website. But (usually) there are many links pointing to the same URL; all the links pointing to the same URL resolve to the same node, and therefore have the same HTTP status code.
The link search tool allows searching by tag, URL, anchor text, nofollow property, internal/external and error status. Results display over a detailed table which can be exported to CSV file. The node search tool filters by title, description, keywords, author and robots meta tag. The result window can locate the node in the tree.
The crawler can be configured for using from 1 to 15 threads. Using a single thread helps building the tree in the order the links (repeated links) appear while crawling. Using two threads is faster and respects the HTTP protocol recomendation: not opening more than two connections to the same server. Using three or more thread increases speed a lot but could be a little aggresive for the target server.
The SEO tool does a basic analysis of title, description and keywords matching the page content. A 100% score means all the words in these fields were found in page content. It doesn’t detect over optimization. This feature will be improved as time goes on. But keep in mind that DRKSpiderJava isn’t mean to be a SEO tool. The SEO analysis is there to help the user make the site more search engine friendly.
DRKSpiderJAVA is a open source software made in Java, which means you can use it, modify it and distribute it to your friends, freely. And it’s multiplatform; you can run it on Windows, Linux, Mac or any other platform supporting Java SE virtual machine.
Features
- Cross platform: runs over Windows, Linux, Mac OSX and any other platform supporting JVM.
- Customizable multithreaded crawler for ultra fast processing.
- Generates a website tree matching site’s navigation hierarchy.
- Can save tree to file for later loading and rechecking
- XML and plaint-text sitemap generators for search engine optimization: generate sitemaps for Google, Yahoo and other engines.
- Detailed information about every link found (Tag, URL, anchor text, status code, nofollow property, depth).
- Export tree or search results to a variety of formats (like CSV) for further processing.
- HTML, CSS and Javascript syntax highlighting with RSyntaxTextArea.
- Web lookup for any tree item.
- Regular expression enabled search
- Advanced link search tool (by tag, URL, anchor, status, nofollow, external)
- Search results locate and highlight in source code window
- Obey robots.txt
- Redirection handling
- Basic SEO analysis
- Cookie support
- Basic HTTP authentication support
Download binary distribution
DRKSpiderJava.zip - 1.5MB - March 7, 2015
DRKSpiderJava.tar.gz - 1.5MB - March 7, 2015
Download the package of your choice, extract and double click on drkspiderjava.jar, or execute the script for your platform. CMD for Windows and SH for Linux or MacOSX.
Download source code
DRKSpiderJavaSrc.7z - 1.3MB - March 7, 2015